今、会社の業務の一部(先月から0.75)でAI、機械学習をやっています。 題材としてSignateの 【練習問題】銀行の顧客ターゲティング をやっています。 業務時間中に色々試せるのはありがたいです。 PythonやR、kerasやGoogle Colaboratoryや Azure上のVM with GPUとか貰って試していたのですが、 結局RapidMiner使ってみました。 KSKのtutorialで勉強して、 色々と回せるようになりました。 確かに簡単ですねこれ。 でも、分かって来るとその限界や欠点も見えてきました。 また、課題に対する知見も溜まってきたので、忘れないうちに。
- 基本的な流れは、
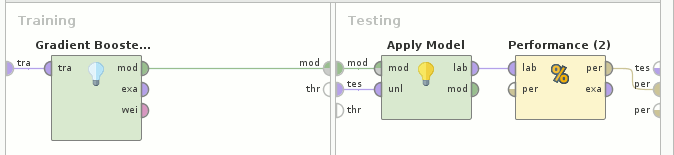
Read CSV(train.csv)→Cross Validation(Gradient Boosted Trees→Apply Model→Performance(Binominal Classification))とRead CSV(test.csv)を合わせて→Apply Model→Select Atributes→Write CSV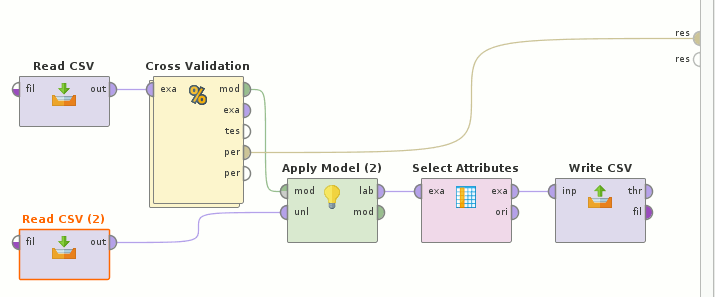
- CSVのreadでは、まず最初の列のidを
id、最後のyをlabelに指定、その他のattributesについては、yes/no 2値のものをbinominal、dayをintegerではなくpolynominalにするのがpointか。 - dayとmonthから日付にしては? と思っていたのだが、pdateを見ると同じ月日でも何百日のものもあって複数yearsありそう、且つyearは特定できなさそう(365日毎でもない)
- ならいっそday/monthをfeatureから落とすと精度が落ちる
- せめてmonthだけでも
dateとして認識できないかと試したがdate format指定をmmmでは出来なかった(小文字だから?) - ウリのAutoModelを試したところ、data file指定、fieldsのcorrelationから落とすattributesを指定、複数種類のmodelを実行、その後modelのparameterをいじれてsimulationが出来、modelに対する理解が進むというもの。AutoModelではGBoostよりDeepLearningが僅差で良かったがAUC 0.89程度
- 自分でcross validationするようにして色々なmodelerを試したところ、Deep Learningも良かったがGradient Boosted TreesがAUC 0.90と最強だった
- なのでGBoostでparameter tuningを。number of treesはdefaultの20からぐっと増やした方が。max depthはちょっとでも大きすぎるとダメ。learning rateもちょっとでも増やすと精度は落ちる
- あんまり細かくtuningしても、結局randomizeの影響が大きい。小数点以下3桁程度のぶれは出てしまう。即ち、全く同じparametersで試しても結果が違う。reproducibleをcheckしても、cross validationの仕方が違うので、全てのrandom性を注意深く固定しないとならないし、randomのseedを探索する事になってしまうのもアホらしい
- 仮にmodelingが出来たとして、これをserviceとして抜き出すのは難しそう。RapidMiner Serverを買えということか。そういうところで彼らは商売をしているのだろう。
- GPUが無くても速い(30秒程度)のは、MultiThreadを使っているからか。
topを見ていると気持ちいいくらいmulti coresを使っている。流石はJavaである。 - よく言われる
XGBoostというmodelerは無く、Gradient Boosted Treesがそれ相当 - one-hot vector化しようと思って
Nominal to Numericalを前処理に入れたら精度が落ちた。その出力をよく見たら、これ単に非numericalなattributesを落としてるだけ。何これ。じゃぁっていうんでNominal to Binomialにしてみても全く同じ。えー、RapidMinerではone-hot vector化、簡単に出来ないの!? 他の言語ではチョー簡単なのに。 - RapidMiner、凄く簡単ですけど、これはinput dataがone fileで数万recordsしか無いから、でしょう。これが画像群だったらこうはいかないでしょう。
現時点で最良の結果(5/11/2018現在68位)
https://signate.jp/competitions/1/leaderboard#scoreboard
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
これ以上AUCを上げるには、 RapidMinerじゃない何か、RかPythonを使って、 入力dataもone-hot vector化して、とかしないとならないような気がします。